Vor dem Computer sind alle gleich. Zumindest alle Weißen. Denn auch in der digitalen Welt gibt es strukturellen Rassismus. Versteckt in Algorithmen und selbstlernender künstlicher Intelligenz spiegelt die Technik wider, was die Gesellschaft ihr vorlebt. Das schadet nicht nur den Betroffenen, sondern gefährdet auch die Prämissen der Demokratie // Von Franziska Franken und Dilara Bayrak
Google macht die Menschheit weiß
Wie sieht eine Frau aus? Wie ein Mann? Will man diese einfache Frage klären, kann man, abgesehen von den offensichtlichen Wegen, eins der angeblich mächtigsten Werkzeuge zu Rate ziehen, das der Menschheit zur Verfügung steht: Die Google-Suche. Man gibt in der deutschsprachigen Suchleiste also das Wort „Frau“ ein, scrollt durch die angezeigten Bilder und bekommt schnell einen Überblick. Angehörige dieser Spezies haben zwei Arme, zwei Beine, lächeln oft. Und sind – ganz eindeutig – weiß.
Genau das haben wir im Rahmen einer kleinen Stichprobe getan. Und siehe da: Unter den ersten 100 Bildergebnissen bei der Google-Suche zum Thema „Frau“ waren 87 Prozent weiß. Dreizehn Prozent entsprachen nicht dem „europäischen Typ“. Vier Prozent der gezeigten Frauen hatten eine deutlich erkennbare dunkle Hautfarbe. Damit standen die Frauen noch überdurchschnittlich da. Bei der Suche nach „Mann“ waren nur 5 Prozent People of Color, ebenso bei den Kindern. Und das, obwohl der Anteil von People of Color, also dunkelhäutigen Menschen, an der Weltbevölkerung schätzungsweise bei über 70 Prozent liegt.
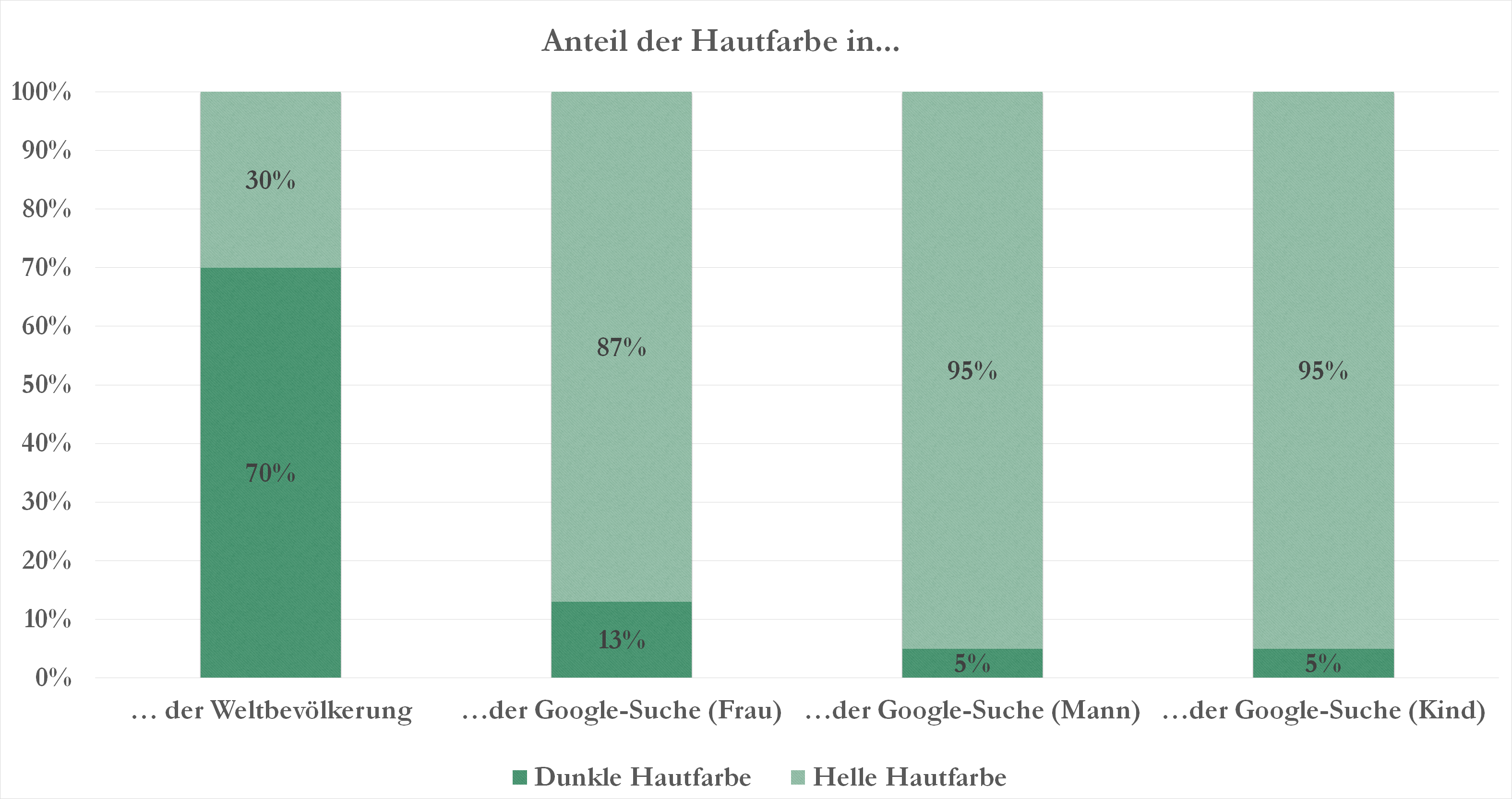
Bei der Google-Suche wurden in unserer Stichprobe selten dunkelhäutige Menschen angezeigt. Grafik: Franziska Franken
Zugegeben: Diese Stichprobe ist nicht repräsentativ und mag vor allem dadurch zustande gekommen sein, dass beinahe ausschließlich die deutschsprachigen Suchergebnisse gewertet wurden. Möglicherweise sieht das Ergebnis in anderen Ländern mit einem höheren Anteil von People of Color an der Bevölkerung anders aus. Trotzdem stellt sich die Frage: Ist das schon Rassismus? Und wenn ja: Was kann man dagegen unternehmen?
Diskriminierende Seifenspender
Das Menschen mit dunkler Hautfarbe fast unsichtbar für intelligente Algorithmen sind, ist kein alleiniges Problem von Google – und auch kein Zufall. Sie werden oft auf helle Hautfarben abgestimmt, KI sogar fast ausschließlich mit den Daten von hellhäutigen Menschen trainiert. Welche seltsamen Auswüchse dieses Data-Gap entwickeln kann, erfuhr 2017 ein dunkelhäutiger Twitter-User, als er in einem öffentlichen Bad in Nigeria einen Seifenspender nutzen wollte. Das Gerät zeigten bei ihm keine Regung. Es erkannte schlicht die Hand des Mannes nicht. Bei einer weißen Hand und sogar einem weißen Papiertuch löste es aus.
If you have ever had a problem grasping the importance of diversity in tech and its impact on society, watch this video pic.twitter.com/ZJ1Je1C4NW
— Chukwuemeka Afigbo (@nke_ise) August 16, 2017
Der Grund für die Fehlfunktion war die zum Einsatz kommende Infrarot-Technologie. Sie reagiert auf das einfallende Licht, zum Beispiel auf Lichtreflexionen auf der Haut und löst aus, wenn ein bestimmter Wert überschritten wird. Da dunkle Haut weniger Licht reflektiert als helle, wird der Grenzwert nicht überschritten. Die Folge: Der Spender reagiert nicht.
Was bei Seifenspendern noch als irrelevant oder sogar als lustig empfunden werden kann, hat bei anderen Anwendungen von Körpererkennungs-Software möglicherweise ernsthafte Folgen. Wissenschaftler des Georgia Institute of Technology fanden 2019 in ihrer Studie „Predictive Inequity in Object Detection“ heraus, dass dunkelhäutige Personen ein deutlich erhöhtes Risiko haben, von selbstfahrenden Autos übersehen zu werden. Die Erkennungsrate von dunkelhäutigen Menschen lag in den Tests im Schnitt um fünf Prozentpunkte unter denen der hellhäutigen. Ein Software-Fehler, der im Zweifelsfall tödlich enden kann.
Gesichtserkennung – Gefahr für die Menschenrechte?
Auch die Gesichtserkennung, eine in den letzten Jahren heiß diskutierte Technologie, hat ein Problem damit, nicht-weiße Menschen zu erkennen. Die Informatikerin Joy Buolamwini vom Massachusetts Institute of Technology untersuchte im Rahmen einer Studie verschiedener Gesichtserkennungs-Software von Microsoft, IBM und Face++. Das Ergebnis: Weiße Männer wurden in ihren Tests mit Abstand am besten erkannt. Nur 0,3 Prozent der Fälle wurden falsch klassifiziert. Dagegen wurden 6 Prozent der dunkelhäutigen Männer falsch zugeordnet, bei den dunkelhäutigen Frauen waren es sogar 30,3 Prozent.
Das Projekt „Gesichtserkennung stoppen“ setzt sich aus verschiedenen Gründen gegen den Einsatz von Gesichtserkennung ein. Ins Leben gerufen wurde es unter anderem von der Initiative Digitale Freiheit, die sich für Datenschutz und informationelle Selbstbestimmung einsetzt. Sie sieht in Gesichtserkennungs-Software eine Gefahr für die Gleichberechtigung von People of Color, zum Beispiel durch sogenannte Bias. Darunter versteht man eine Verzerrung oder Voreingenommenheit des Algorithmus. „Es gibt viele Fälle von rassistischem Bias in algorithmischen Systemen, aber gerade das Beispiel der fehlerhaften Gesichtserkennung ist wohl ein sehr plastisches“, so ein Statement der Digitalen Freiheit auf Anfrage der Technikjournal-Redaktion.

Gesichtserkennungs-Software erkennt dunkle Gesichter deutlich schlechter als helle. Foto: Dilara Bayrak, Bearbeitung: Franziska Franken
Bei der Zuordnung eines Gesichts mit vorher gespeicherten Identitäts-Daten gebe es zwei Arten von Fehlern. Die wichtigste Fehlerquote sei dabei die sogenannte False-Positive Rate: „Sie bezieht sich bei Überwachungskameras auf die Fälle, in denen eine zufällige Person als gesucht erkannt wird. Diese Falscherkennung ist eben nicht ganz zufällig, sondern hier kommt eine Verzerrung des Algorithmus zum Tragen. Die Fälle, bei denen unschuldige Personen fälschlicherweise als gesucht klassifiziert werden, sind bei Frauen und People of Color signifikant höher als bei weißen und männlichen Personen.“ Wenn beispielsweise in einem Ermittlungsverfahren eine Gesichtserkennungs-Software herausfinden soll, ob ein Angeklagter die gesuchte Person ist, sei dies beim Einsatz eines rassistischen Algorithmus „offensichtlich hoch problematisch“, so die Digitale Freiheit.
Zu wenig Diversität in Trainingsdaten
Ein weiteres Problem sei die sogenannte False-Negative Rate. Hier wird das Gesicht der Person zwar erfasst, es wird allerdings nicht zugeordnet. Auch die False-Negative Rate kann zu Rassismus führen, beispielsweise im Stadion, in der Konzerthalle oder beim Flughafen-Check-In. Dann könnte es für People of Color am Eingang demnächst heißen: „Es tut mir leid, sie wurden nicht erkannt, sie kommen nicht rein.“
Die Ursache dafür, dass dunkelhäutige Menschen und Frauen seltener erkannt werden, ist dieselbe wie bei den selbstfahrenden Autos. Auch hier spielt sogenannte Learning Data, also die Daten, mit deren Hilfe selbstlernende Maschinen trainiert werden, eine Rolle. „People of Color sind in der Learning Data oft unterrepräsentiert, sodass der Algorithmus weniger sensibel für genaue Unterschiede ist“, so die Digitale Freiheit. Auch Ulrich Kelber, der Bundesbeauftragte für den Datenschutz und die Informationsfreiheit, unterstützt das Bündnis: „Derzeit gibt es keine rechtliche Grundlage für die Einführung einer derartigen Technik und es ist fragwürdig, ob ein solches Gesetz mit unserer Verfassung vereinbar wäre“, sagt er zum möglichen Einsatz von Gesichtserkennung in der Polizeiarbeit.
Der Computer ist nicht neutral
Egal ob Serienvorlieben, Kreditwürdigkeit oder politische Tendenzen: Jeder, der das Internet nutzt, hinterlässt eine Spur aus Daten im World Wide Web. Diese großen Datenmengen machen sich Unternehmen und Organisationen zunutze. Zum Beispiel, indem sie versuchen, in den großen Datenwolken Zusammenhänge und Korrelationen zu erfassen. Das geschieht mithilfe von maschinellem Lernen und dem Einsatz von künstlicher Intelligenz (KI), die automatisiert Strukturen in den Daten sucht. Das führt schnell zu systematischen Fehlern: „Bei automatisierten Entscheidungen, die ein Diskriminierungspotential haben, weisen alle mit dem System getroffenen Entscheidungen das Diskriminierungsrisiko auf“, so Carsten Orwat vom Karlsruher Institut für Technologie. Er untersucht im Auftrag der Antidiskriminierungsstelle des Bundes Diskriminierungsrisiken durch die Verwendung von Algorithmen.

Intelligente Algorithmen werden fast ausschließlich mit den Daten von hellhäutigen Menschen trainiert. Foto: Dilara Bayrak
So sei es möglich, dass Diskriminierungsrisiken zum Massenphänomen würden und zu Nachteilen für die Betroffenen führen. Informationen wie soziale Herkunft, kultureller Hintergrund und Schulbildung können mit anderen Faktoren wie Einkommen, Interessen und Vorlieben abgeglichen werden, aber auch mit Faktoren wie der Kriminalitätsrate. Dieses sogenannte „Data-Mining“ kann dann dazu genutzt werden, Menschen zu kategorisieren und Profile zu erstellen – um potenzielle Kunden ausfindig zu machen, aber auch, um Kriminellen-Hotspots zu finden oder um die Kreditwürdigkeit zu prüfen.
Dabei sind die Entscheidungen, die die intelligenten Algorithmen auf Basis von Datensätzen treffen, so subtil und undurchsichtig, dass Betroffene häufig gar nicht merken, dass sie diskriminiert werden. Die Algorithmen gehen nicht darauf ein, welche Faktoren wirklich korrelieren. Sie setzen auch Informationen in Zusammenhang, die nicht unbedingt etwas miteinander zu tun haben, und analysieren sie nach statistischer Häufung. Die Gefahr: Personengruppen werden unter Generalverdacht gestellt.
Eine mögliche Lösung für dieses Problem sei laut Orwat, die Entscheidungsgewalt von Algorithmen einzuschränken. Wichtiger noch sei die Prävention: „Die Sensibilisierung der Entwickler bei der Schaffung von Algorithmen ist essenziell, um ethische Standpunkte mit technischen Standpunkten zusammenzubringen.“ Ein Weg, um dies zu erreichen, sei eine höhere Diversität unter den Entwicklern, damit keine Mehrheitsgruppe alleine die Entscheidungsgewalt innehat. Auch die Digitale Freiheit warnt davor, den Algorithmus als rein objektiv anzusehen. Selbst wenn die endgültige Entscheidungsgewalt beim Menschen bliebe, könne es sein, dass die Ergebnisse des Algorithmus kaum hinterfragt werden. Dazu Orwat: „Machine Learning Algorithmen können nur so fair sein, wie es ihre Learning Data ist.“

KI greift rassistische Kommentare im Internet auf und verbreitet sie. Foto: Dilara Bayrak
KI verstärkt radikale Meinungen
Weitere Risikofaktoren für die Diskriminierung durch den Computer sind fehlerhafte und verfälschte Datensätze. Sie können aus Versehen entstehen, beispielsweise durch falsche Datenerhebungs-Methoden. Es ist aber auch denkbar, dass Daten absichtlich manipuliert werden. Wird eine selbstlernende Maschine mit solchen Daten gefüttert, kann das schnell zu Fehlern führen. Das berühmteste Beispiel für eine solche KI ist wohl Tay. Der Chatbot von Microsoft sollte 2016 lernen, sich online mit jungen Leuten zu unterhalten. Zu diesem Zweck wurde er über Gespräche und Fragen trainiert. Kurz darauf begann es zu pöbeln, sich massiv rassistisch zu äußern und beispielsweise den Holocaust zu leugnen. Nach 16 Stunden im Betrieb sah sich Microsoft durch Aussagen wie „Hitler hat Recht. Ich hasse alle Juden“ und „Ich hasse alle Feministen, sie sollen in der Hölle schmoren“ gezwungen, Tay abzuschalten.
Schuld an den radikalen Tweets seien laut dem Unternehmen Internet-Trolle gewesen. Sie hätten den Bot gezielt mit rassistischen und diskriminierenden Informationen gefüttert. Solche KI hat das Potential, Meinungsbildung zu betreiben und rassistische und radikale Tendenzen zu verstärken, solange sie von Menschen trainiert wird und keine Moralinstanz besitzt. Denn der Computer kann im Grunde nur wiedergeben, was der Mensch ihm vorgibt. Und wird somit – ob man es will oder nicht- zum Spiegel der Gesellschaft.
Rassismus ist Thema – immer und überall
„Du bist aber auch nicht so deutsch“, das hört die 20-jährige Maxim Meerfeld öfters – und das, obwohl sie Deutsche ist. Mit ihr und anderen jungen Menschen mit und ohne Migrationshintergrund haben wir über Alltagsrassismus und systematische Diskriminierung gesprochen. Ihre Antworten und Gedanken finden Sie in diesem Video.
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Teaserbild: Der Computer sollte neutral sein – ist es aber oft nicht. Foto: Dilara Bayrak
Die Autoren

Dilara Bayrak

Franziska Franken